
Grass Protocol: An API Key to the Internet

Disclosure:
ASXN and ASXN staff have exposure to Grass. Additional disclaimers can be found at the end.
Introduction
Overview of Grass Protocol
Grass is a decentralized network which focuses on web scraping, live context retrieval and web data collection for AI. Its main goal is to decentralize and democratize web data collection and retrieval through an incentive mechanism while rewarding users who contribute their resources.
The network is currently scraping over 100 terabytes of data per day. It manages everything from initial data collection through processing and verification, while rewarding and incentivizing participants.
As of now, Grass nodes run across 190 countries, with over 2.5 million nodes. The protocol has seen increased interest and usage over the past few months.
Grass Protocol consists of:
Grass nodes, which enable users to contribute unused network resources to earn rewards. Each node is uniquely identified by its device fingerprint and IP address.
The Sovereign Data Rollup, a purpose-built network on Solana, which enables the protocol to handle everything from data sourcing to processing, verification and structuring into data sets.
The network is built around validators which issue data collection instructions, routers which manage web request distribution, and nodes, which are the users who contribute their unused network resources. It uses data ledgers for hash storage, a Merkle tree bundling system, and onchain root data posting.
Grass nodes can be deployed through a desktop application, browser extension or Android-based mobile application. For data processing, the protocol employs HTML to JSON conversion systems, custom Python cleaning scripts, data structuring tools, and vectorization processes, while developing embedding models for edge processing. Security and verification are maintained through ZK TLS, proof generation for web requests, web session recording, a decentralized database for hash storage, and anti-poisoning measures.
Industry Overview
AI Overview
Artificial intelligence, which is broadly the ability of machines to perform cognitive tasks, has quickly become an essential technology in our day to day lives. The breakthrough in 2017 occurred when transformers were developed to solve the problem of neural machine translation, which allows a model to take an input sentence of a task and produce an output. This enabled a neural network to take text, speech, or images as an input, process it, and produce output.
OpenAI and Deepmind pioneered this technology and more recently the OpenAI GPT (Generative Pre-trained Transformer) models created a eureka for AI with the proliferation of their LLM chatbots. GPT-1 was first introduced in June of 2018, featuring a model composed of twelve processing layers. It used a specialized technique called "masked self-attention" across twelve different focus areas, allowing it to understand and interpret language more effectively. Unlike simpler learning methods, GPT-1 employed the Adam optimization algorithm for more efficient learning, with its learning rate gradually increasing and then decreasing in a controlled manner. Overall, it contained 117 million adjustable elements, or parameters, which helped refine its language processing capabilities.
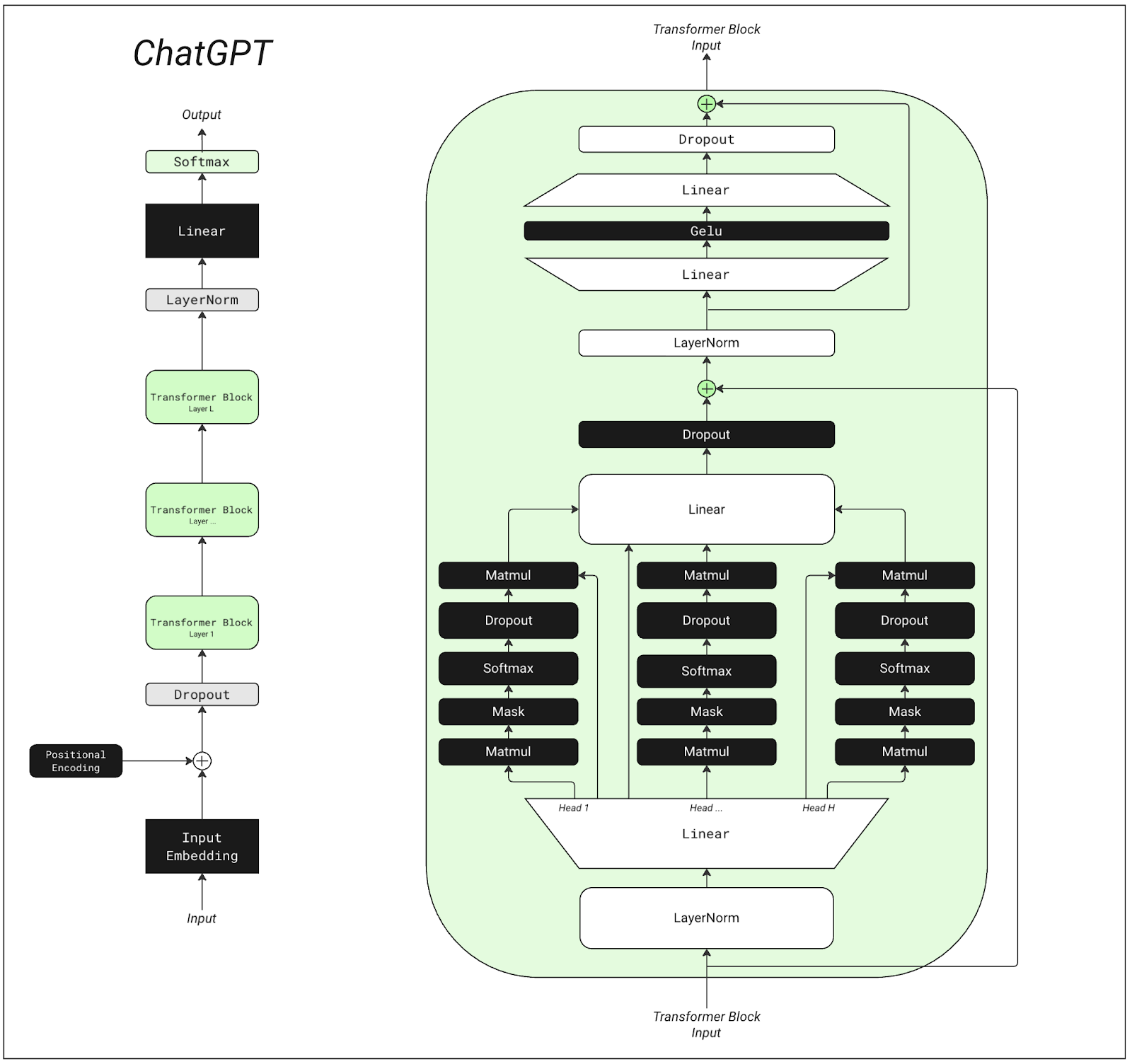
Fast forward to March 14th 2023, OpenAI released GPT-4, which features approximately 1.8 trillion parameters spread across 120 layers. The increase in parameters and layers enhances its ability to understand and generate more nuanced and contextually relevant language, among other things. The over 10,000x increase in the number of parameters in OpenAI’s GPT models in under 5 years shows the astounding rate of innovation happening at the cutting edge of generative models.
So then, how is an LLM model generated?
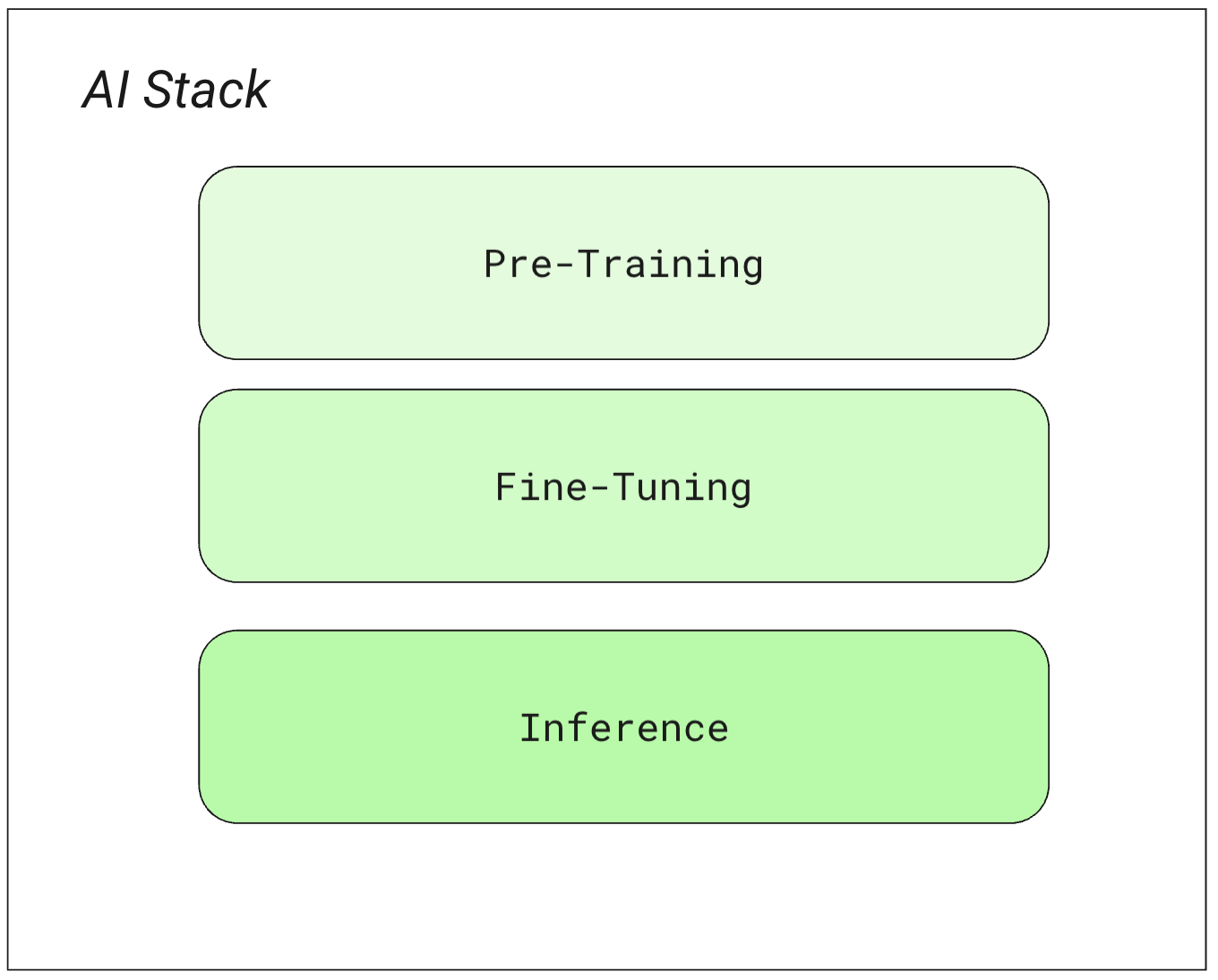
An LLM is generated and used via three key steps; pre-training, fine-tuning & inference. We look at each stage of the training process:
Pre-Training
Pre-training is the foundational step where a model learns a broad range of knowledge from a large and diverse dataset. Before transformer-based architectures, leading NLP models relied on supervised learning, which required extensive labeled data and was largely confined to corporations with the resources to handle the costs of annotation and development. This restricted their scalability. The introduction of transformer-based architectures enabled unsupervised learning, allowing models to train on unlabeled data, which significantly broadened their applicability. A broad overview of the pre-training process is therefore something like this:
Data Collection & Preparation - The first step in pre-training involves gathering a vast corpus of text, such as books and websites, which is then cleaned and processed. The data is then tokenized. Tokenization breaks down text into smaller units (words, parts of words, or characters), and the data is transformed into numerical values, often using word embeddings, making it suitable for the model to process.
Model Architecture - The choice of model architecture is critical, especially for language models where transformer-based frameworks excel in handling sequential data. Initial parameters like network weights are set, which will be refined during training to optimize performance.
Training Procedure - During the training phase, the model learns patterns from the text using two key processes: the learning algorithm and the loss function. Backpropagation, a core learning algorithm, calculates how much each parameter contributes to prediction errors. Optimization algorithms like Stochastic Gradient Descent (SGD) and Adam adjust these parameters, with Adam offering faster results by adjusting learning rates dynamically. Loss functions, such as Mean Squared Error for regression or Cross-Entropy Loss for classification, measure prediction accuracy and guide the model to improve over time.
Resource Allocation - Training large-scale models requires substantial computational and financial resources. Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs) handle the intensive parallel processing, while distributed computing across multiple machines helps process vast datasets efficiently. The energy demands and costs for storage, hardware, and cloud computing services are substantial, with GPT-4 reportedly costing over $100 million to train.

Scale records on the model GPT-3 (175 billion parameters) from MLPerf Training v3.0 in June 2023 (3.0-2003) and Azure on MLPerf Training v3.1 in November 2023 (3.1-2002). Source: Microsoft
Fine-Tuning
The fine-tuning stage adapts a pre-trained model to specific tasks or datasets by retraining it on curated data. This process, which involves adjusting the model’s architecture and parameters, allows for superior performance on targeted applications like text classification or sentiment analysis. Advanced models like GPT-3 also use Reinforcement Learning from Human Feedback (RLHF), where human reviewers help fine-tune outputs, ensuring alignment with human preferences.
Inference
The final stage, Inference, is the application of the trained model to new data for predictions or decisions. The model processes input (e.g., class labels, numerical values) in a format consistent with its training. Inference can be batch-based (for large datasets) or real-time (for immediate feedback). Key performance factors during inference include latency, throughput, and resource efficiency, with trade-offs between edge and cloud computing based on deployment needs.
Centralizing Forces Within Model Generation
In the process of creating an AI model, numerous centralizing and monopolistic forces come into play. The significant resources needed for every phase of development pave the way for economies of scale, meaning that efficiency improvements tend to concentrate superior models in the hands of a select few corporations. Below, we detail the diverse issues with data in AI:
Pre-Training
As we have seen, the pre-training phase of a model combines a few things: data, training and resources. When it comes to the initial data collection, there are a number of issues:
Access to data & Centralization
The pre-training phase requires a large corpus of data, typically from books, articles, corporate databases and from scraping the internet. As we discussed, when supervised learning dominated as a training technique, the large companies like Google could create the best models due to the large amount of data they were able to store from users interacting with their search engine. We see a similar centralizing and monopolistic force throughout AI today. Large companies such as Microsoft, Google & OpenAI have access to the best data through data partnerships, in-house user data or the infrastructure required to create an industrial internet scraping pipeline.

The top 1% of x networks, facilitates x proportion of the total traffic / volume. Source: Chris Dixon's "Read Write Own".
Transformers enabled unsupervised learning models but the scraping of web data is no easy feat, web pages typically ban scraper IP addresses, user agents and employ rate limits and CAPTCHA services.
AI companies deploy a variety of tactics to navigate around the barriers websites put in place to obstruct data collection efforts. One common method involves utilizing a diverse array of IP addresses to sidestep IP-based rate limiting or outright bans, often achieved through the use of proxy servers or VPN services. Additionally, altering the user-agent string in HTTP requests—a technique known as User-Agent Spoofing—allows these companies to emulate different browsers or devices, thereby potentially circumventing blocks aimed at user-agent strings typically associated with automated bots or scrapers. Furthermore, to overcome CAPTCHA challenges, which are frequently employed by websites to prevent automated data collection, some AI companies turn to CAPTCHA solving services. These services are designed to decode CAPTCHAs, enabling uninterrupted access to the site's data, albeit raising questions about the ethical implications of such practices.
Beyond their ability to gather large amounts of data, big corporations also have the financial means to build strong legal teams. These teams work tirelessly to help them collect data from the internet and through partnerships, as well as to obtain patents. We can see this happening today with OpenAI and Microsoft, who are in a legal dispute with The New York Times. The issue is over the use of The New York Times' articles to train the ChatGPT models without permission.

Patent Centralization. Source: Statista
Closed source data / Data quality
There are also ethical and bias considerations involved in training a model. All data has some inherent bias attached to it since AI models learn patterns, associations, and correlations from their training data, any inherent biases in this data can be absorbed and perpetuated by the model. Common biases we find in AI models result from sample bias, measurement bias and historical bias and can lead to AI models producing poor or unintended results. For example, Amazon trained an automated recruitment model which was designed to assess candidates based on their fit for different technical positions. The model developed its criteria for evaluating suitability by analyzing resumes from past applicants. However, since the data set it was trained on included predominantly male resumes, the model learned to penalize resumes that included the word “women”.
Data Provenance & Verification
Led by AI, data generation is increasing exponentially, from 2 Zettabytes in 2010 to an estimated 175 Zettabytes in 2025. Forecasts predict a surge to over 2000 Zettabytes by 2035, indicating a growth rate exceeding 10 times in the next 15 years. This is in part due to the creation of AI generated content, in fact, a report into deep fakes and AI generated content by Europol estimated that AI-generated content could account for as much as 90% of information on the internet in a few years’ time, as ChatGPT, Dall-E and similar programs flood language and images into online space.

The inherent biases in an AI model's outputs are often a reflection of the data on which it was trained. Consider the potential pitfalls of using data harvested by industrial-scale internet scrapers for pre-training: with the proliferation of AI-generated content online, there's a heightened risk of feeding models with inaccurate or skewed data. A clear manifestation of this issue is observed in Google's Gemini LLM, which, in its quest for equitable representation, might introduce historically inaccurate elements into generated content.
Protocol Mechanics
High-level overview of the scraping process
Grass Protocol's distributed network coordinates validators, routers, and nodes to scrape and collect web data. Its infrastructure enables parallel processing at scale while allowing access to difficult to scrape data through strategic IP address management.
Validators send a set of instructions for scraping targets. For example, this set of instructions could be along the lines of "scrape this website from the year 2024 onwards". This set of instructions is sent as web requests, which are then processed by routers. Routers on the network receive these web requests and distribute them to nodes on the network. Each web request could be different, which enables parallelized scraping. For example, if the goal is to scrape a website with 100,000 pages, 100,000 requests would be dispersed among nodes, who would each hit different pages and download all of the data at once.
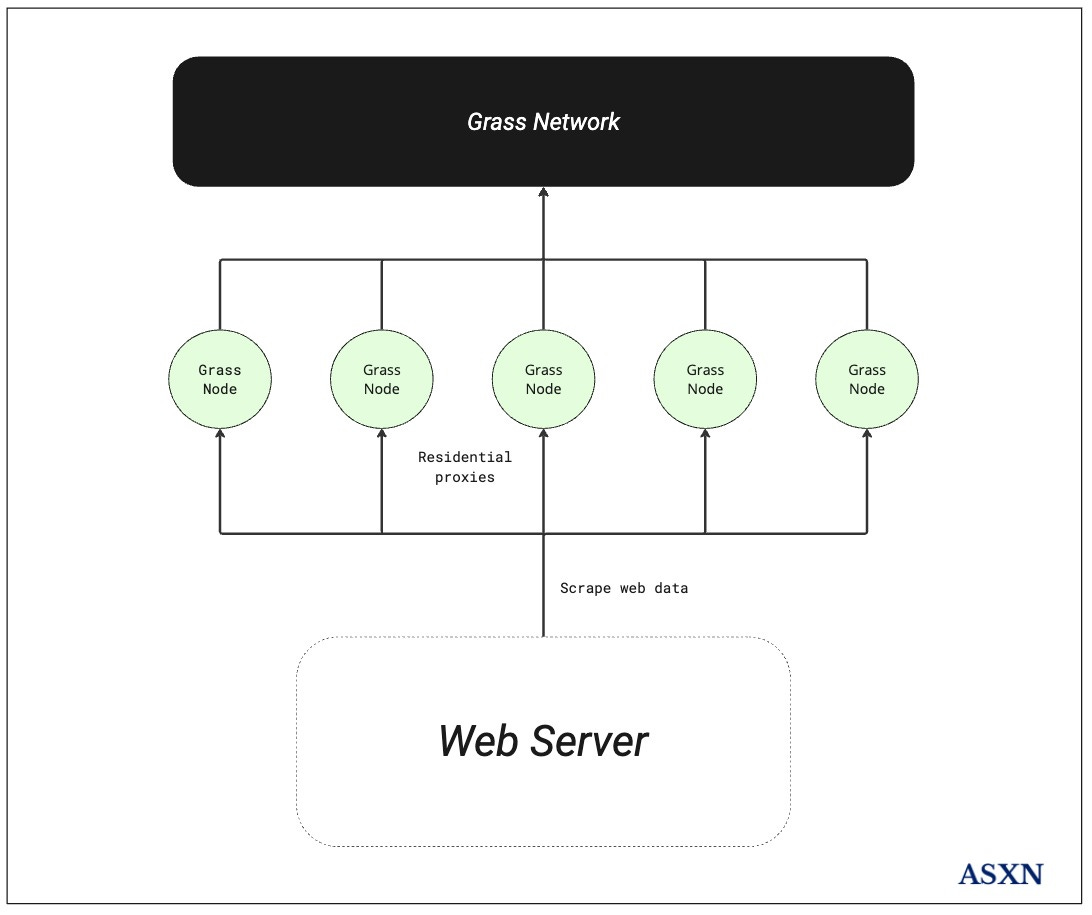
Apart from being parallelized, since the protocol is using residential IP addresses, they are able to bypass gate kept information. IP addresses across the globe are typically bucketed into two categories:
Residential IP addresses
Data center IP addresses
Typically, data center IP addresses are blocked, while residential traffic is not. Since residential traffic from Grass nodes and from natural traffic cannot be differentiated, Grass is able to bypass websites that may block data center IPs to gatekeep data, as well as avoid honeypots and rate limiting. It's also important to note that Grass does not collect private user data through the Grass nodes. Nodes use extra, unused bandwidth to scrape and read publicly available websites, they only collect the device's fingerprint (IP address), while all other data remains completely anonymous.
Node operation and participation
Grass nodes enable users to contribute their unused bandwidth to scrape web data and earn rewards in return. Users can install Grass Nodes via a desktop app, their Solana Saga app, and in the future, through iOS mobile apps and a purpose-built hardware device. Each node is uniquely identified by its device fingerprint and IP address. Currently, the network has over 2.5 million active nodes. The network can handle approximately 70 web requests per session per node.
Grass node operators are incentivized for web requests they relay. They use their unused bandwidth to access websites and scrape data. At a high level, nodes receive requests from routers that are distributed from validators. Nodes relay outgoing web requests to public websites, and return encrypted web server responses to their corresponding router.
Outgoing web requests are sent to Grass Nodes as encrypted data packets, which direct nodes on the destination of each data packet. Each web request is authenticated to verify the authenticity of each request and to verify the targeted website to scrape.
Per Grass Node, the network resources that will be utilized could be up to 30 gigabytes per month, however, actual individual figures depend on nodes geography and where demand is for certain types of web data.
Nodes are rewarded based on their reputation score as well as geographical demand:
Node reputation scores are a function of: completeness (i.e., is the data complete and whole for the specific use case), consistency (i.e., is the data uniform across different data sets and timelines), timeliness (i.e., is the data up-to-date), and availability (i.e., is the data available from each node).
Websites display different information based on node locations, which can be more or less valuable depending on the use case of the data. Additionally, latency is very important. If a web server is hosted in Europe, and the network is attempting to relay web requests through a node that is geographically further away (i.e., in Asia), it'll take longer and will be less efficient. Therefore, if a dataset requires scraping of websites hosted in Europe, European nodes are going to be more valuable compared to North American or Asian nodes.
In addition to nodes crawling and scraping the internet, they will be also used to tag and label data in the future as well.
Grass recommends that users run nodes on their mobile devices (not live yet, apart from on the Solana Saga) or through their desktop node application. Mobile devices tend to perform better than browser extensions as their fingerprint is generally more likely to be considered to be human. In addition, mobile devices are more difficult to be blocked due to the way that IP addresses are distributed. There are no more unique IPv4 addresses, which is the IP addressing protocol that is used across the internet, which can be assigned. Therefore, typically IPv4 addresses are shared amongst phones in certain areas based on the cell tower that they connect to. This makes it difficult to block IPv4 addresses since it would lead to blocking all users which correspond to an IPv4 address. In addition, bot detection for mobile devices is more difficult compared to personal computers. By adding random time spacing between taps on a mobile device, the protocol makes it harder to differentiate from a normal user.
Apart from mobile devices, users can also download a desktop app, which is comparatively more efficient than the browser extension, as it:
Uses less resources, memory specifically, on their computer, as it's not limited by the memory that the browser itself is using.
Is capable of scraping nearly 10 times as much data and information.
Data collection and processing
The protocol currently has over 2.5 million nodes. While the protocol still only had 1 million nodes, it was able to scrape 15 million articles per day, and has scraped different subreddits across Reddit, as well as the entirety of Reddit data from 2024 in under a week.
The web data that is scraped, initially, is simply the content that the server sent back to the node, which is often unusable HTML code. This HTML snippet is cleaned, processed and restructured - with HTML elements removed. In addition, sensitive data or data that may not be necessary can be dropped during this process.
By the end of the cleaning and restructuring process, the data is formatted into a structured dataset in the form of a JSON file. The dataset that exists in the JSON file is still not fit for LLMs: it has to be converted into tokens. These tokenized datasets are then transformed into vectors and arrays of numbers, which models can train on. The protocol might also use synthetic data at this stage and lean on recursive training.
Currently, most of this tokenized and processed data is stored on Hugging Face, up to 10 terabytes per day. For other, more proprietary datasets, the protocol hosts them on MongoDB. Grass currently handles data cleaning, reformatting and structuring centrally for efficiency. Grass recently announced that they are working on a heavier, hardware device, which will allow users to run additional forms of edge compute workloads in addition to scraping. These hardware nodes would be able to complete parts of the downstream data tasks that Grass currently handles on centralized servers, such as cleaning the data that they scrape and restructure it into formats that LLMs can read.
In addition to allowing heavier hardware nodes to participate in data processing and restructuring, Grass is also training a model with 7 billion parameters that can help convert any raw HTML into a structured dataset.
Sovereign Data Rollup on Solana
Grass is launching a sovereign data rollup on Solana to mitigate data poisoning, ensure data provenance, and enable efficient protocol scaling. Websites detect crawlers and scrapers through IP address verification, device fingerprint analysis, and traffic pattern analysis. They respond by falsifying data, creating honeypot traps, generating deceptive link networks to waste compute resources, or dynamically adjusting prices and information. Grass utilizes retail and residential proxy addresses to counter these measures. Dataset compilation faces additional poisoning vectors through:
Inserting biased content
Following SEO manipulation patterns
Introducing subtle biases affecting model training
Modifying existing entries to alter model behavior
Websites engage in data poisoning to protect commercial interests, particularly regarding competitive data they consider valuable. Companies may also poison data to influence advertising and SEO systems.
Data poisoning significantly impacts LLMs by introducing biases into AI training data. This poses particular risks for political and social content, where private or public entities might attempt to shape public opinion through manipulated AI responses. Given these implications, verifying data and its sources becomes essential for AI models.
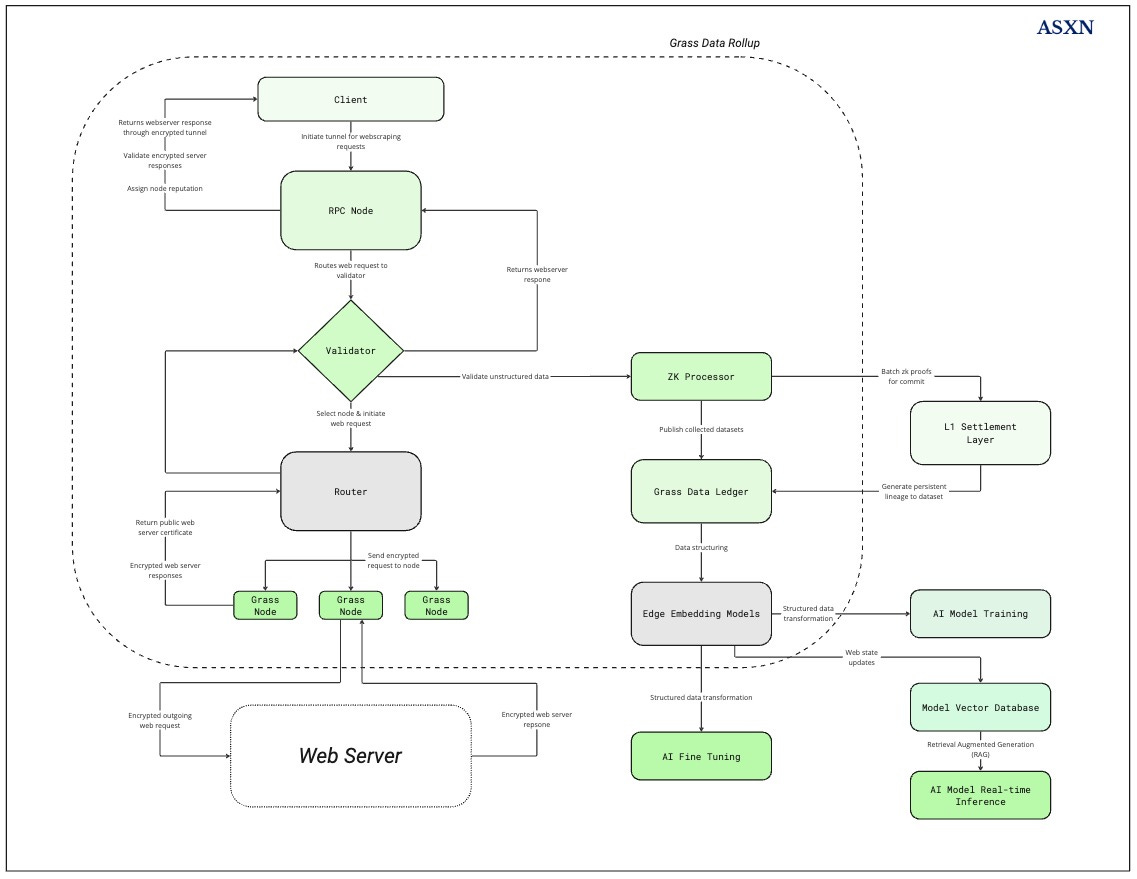
To ensure data provenance and integrity, the network generates proofs verifying that dataset components were scraped from specific websites at recorded times. These proofs are generated for every web request sent to Grass nodes.
When a Grass Node receives an encrypted response containing requested data, the network generates metadata including the website's URL, IP address, session keys, timestamp, and dataset. Validators track both data origin and the responsible scraping node.
The metadata and dataset are processed by the ZK processor, which creates and batches proofs before settling them on Solana Mainnet. While the proofs settle on Solana, the actual datasets reside in the Grass Data Ledger. These Mainnet proofs reference their corresponding ledger datasets. The data ledger serves as a permanent record where users can verify AI model training data and confirm its integrity.
Since validating individual web request proofs would overwhelm the L1, Grass developed a sovereign data rollup with a ZK processor to batch metadata for validation. This will become increasingly relevant as Grass expands its node count and per-node efficiency; as the transaction volume required for dataset verification could burden Solana. The Jupiter TGE demonstrated chain congestion and transaction failures - Grass could potentially generate comparable or up to ten times higher daily transaction volumes for data proofs.
Validators and routers
Validators
Validators perform two core functions: sending web scraping instructions and verifying web transactions and traffic quality.
For web scraping instructions, validators create structured tasks specifying:
Target websites
Required data types
Time frames
Specific content identifiers
These structured tasks are formatted into instructions which routers can process and distribute to nodes.
For verification of data, validators authenticate and encrypt data transactions through multiple mechanisms:
Validators establish TLS handshakes with routers using private keys for transactions. Router-transmitted traffic, including server responses and node reputation scores, flows through TLS connections using cipher suites.
Validators generate and maintain keys to validate unstructured data and traffic quality from Grass nodes.
Validated data transfers to the ZK processor, which generates proofs of datasets and metadata, including website URLs, IP addresses, session keys, timestamps, and datasets. These are batched and settled on Solana Mainnet.
As of date, the validator is centralized. The protocol plans on introducing multiple validators and a consensus mechanism to facilitate data transfers.
Routers
Routers distribute and relay web requests across geographic regions, serving nodes within their designated areas. They receive task instructions from validators and distribute encrypted requests to Grass nodes.
After nodes return encrypted responses, routers provide these responses to validators along with node reputation scores, request sizes, latency metrics, and individual node network status.
ZK Processor and Grass Data Ledger

Data Ledger
The Grass data ledger creates an immutable record of web scraping activities, enabling verifiable proof of data provenance for datasets and addressing source-level and retroactive data poisoning issues.
Datasets scraped through the Grass protocol, along with their metadata, are permanently stored on the data ledger. Metadata proofs are posted to Solana mainnet and maintained on the data ledger.
Data provenance records the origin, creation method, timing, location, and creator of data. This metadata authenticates data and validates its reusability. For AI labs, data provenance ensures data integrity and reliability during model training.
ZK Processor
The ZK processor settles metadata on Solana, while ensuring that the dataset is not visible to all Solana validators. It generates and batches proofs before posting them. The processor receives validated, unstructured data from validators and publishes it to the data ledger. Effectively, it functions as a gateway between validators, the data ledger, and Solana mainnet, publishing validated data to the ledger while posting batched proofs to Solana mainnet.
Metadata proofs serve dual purposes: establishing data provenance and lineage, while identifying specific network nodes that routed data, enabling proper rewarding for their services.
Value Proposition
As we have discussed, the collection of data in order to train models is vital, however, the following issues are prevalent:
Data Access - Major firms like Microsoft, Google, and OpenAI have superior data access through partnerships, their own user data, or the capability to establish extensive web scraping operations.
Closed-Source Data - When Training models the data used requires careful consideration of bias.
Data Provenance - Determining and verifying the source of data is becoming increasingly important, as it ensures the integrity and reliability of the data which is crucial when training a model.
Decentralized data collection for AI
Up to 80% of the effort in deploying AI models is dedicated to data preparation. This task becomes more time-consuming and complex with fragmented or unstructured data, with exporting and cleansing being the two critical steps in the process. The competitive landscape of AI is intensifying as major websites with investments or strategic partnerships in centralized AI entities take measures to safeguard their position by restricting smaller contenders' access to vital data. These websites have adopted policies that effectively make data access prohibitively expensive, excluding all but the most well-funded AI laboratories. They frequently employ strategies such as blocking IP addresses from recognized data centers, and in some cases, they engage in intentional data poisoning—a tactic where companies deliberately corrupt shared data sources to disrupt their rivals' AI algorithms.
Valid residential IP addresses and user-agents therefore hold significant value, as they enable the collection of internet data in a way that ensures the mass retrieval of accurate information. Every ordinary internet user possesses this potential, and if leveraged collectively within a network, it could facilitate the extensive indexing of the web. This, in turn, would empower open-source and decentralized AI initiatives by providing them with the vast datasets necessary for training. The use of token rewards to accurately reward participation in this DePIN network can enable this network to compete with the likes of Google and Microsoft who are the only entities who have indexed the whole internet.
The Grass DePIN flywheel works as follows:
Individuals participating in the network's growth (nodes, routers, data providers) are motivated through token rewards, effectively subsidizing their efforts. These rewards are designed to bolster the network's early development until it can generate steady revenue from user fees.
The expansion of the network draws in developers and creators of products and services. Furthermore, the network's financial support for users who supply its services enables them to provide these services at lower costs, which in turn entices end users.
As end users start to pay for the services offered by the network, the revenue for both the providers and the network itself rises. This increase in revenue generates a positive feedback loop, drawing in additional creators, developers, and providers to use and participate in the network.
Creators, developers, and providers are rewarded for their support of the network . The opportunity for these users to be rewarded for their efforts perpetuates a beneficial cycle of network adoption and proliferation, creating more opportunity for creators, developers, and providers to deploy their support, products, and services and create value.
Utilizing DePIN to compile publicly accessible data could address the problem of proprietary datasets in AI, which often embed biases in the resultant models. Training open-source AI models on data from such a network would enhance our ability to detect, assess, and correct biases. Currently, the opaqueness surrounding the datasets used for training AI models hinders our understanding of the biases they may contain, compounded by the difficulty in contrasting models trained on diverse datasets. The creation of this decentralized data network, could incentivise various contributors to provide datasets with clear provenance, while also enabling the tracking of how these datasets are utilized in both the initial training and subsequent fine-tuning of foundational AI models.
Supply Bootstrapping
Excluding DePIN protocols, typically token generation events are a later stage milestone for most protocols. Tokens represent governance rights for the project and the DAO, and lack relevance in most cases. Grass, similar to other DePIN protocols, will use their token to incentivize growth and bootstrap supply - by incentivizing users through Grass to increase node counts and maintain steady uptime for good quality data.
User-Owner Misalignment
In the Web 2.0 model, a fundamental misalignment exists between the users of a network and its developers or owners. Many networks and platforms begin with an open-source or open-innovation ethos, only to later prioritize shareholder value, often at the expense of their user base. For-profit corporations frequently introduce take rates and other monetization tactics to meet their goals of maximizing shareholder value.
Historically, many platforms have transitioned from open ecosystems to more controlled, centralized models. Facebook, for example, initially supported open development through public APIs to encourage innovation but later restricted access to apps like Vine as they grew in popularity. Similarly, Voxer, a messaging app popular in 2012, lost access to Facebook’s “Find Friends” feature, limiting its ability to connect users. Twitter, which originally embraced openness and interoperability by supporting the RSS protocol, prioritized its centralized database by 2013, resulting in the loss of data ownership and the disconnection of user social graphs. Amazon has faced criticism for allegedly using internal data to replicate and promote its products over those of third-party sellers.
Google’s multiple antitrust cases reveal how they “willfully acquired or maintained monopoly power” to the detriment of both users and companies building on its platforms, such as Epic Games. These cases illustrate a recurring trend: platforms move toward greater control, not from malicious intent, but due to the inherent incentive structures of shareholder-driven corporations. This shift often impacts both innovation and the broader digital community and thus transplanting this oligopolistic Web2 model onto a technology that is far more influential than social media—and holds the capacity to profoundly influence our decisions and experiences—presents a concerning scenario.
Grass aims to fundamentally transform this incentive structure by aligning the network's interests directly with its users. In this model, users hold ownership of the network and are rewarded for contributing bandwidth and generating value as they engage with websites (instead of a single corporation such as Google capturing all of that value). Andrej further points out that decentralizing AI should be a user-centric endeavor, adopting a peer-to-peer structure purely for the sake of decentralized AI often reduces performance (such as geographically distributed training) and can become inefficient and fail to solve pressing issues. Instead, this approach prioritizes aligning network benefits directly with user participation, cultivating a more equitable and user-centered ecosystem.
Data provenance and quality assurance
In an era where AI and deep fakes are set to dominate, determining the origin and accuracy of data is crucial. With projections suggesting that up to 90% of online content will soon be AI-generated, the average person may struggle to tell real information from fabricated data. The world urgently needs a way to verify the provenance of AI training data, and Grass is stepping up to fill this gap.
Grass is building a system where every time data is scraped by its nodes, metadata will be captured to confirm the exact source website. This metadata will be embedded in each dataset, allowing builders and developers to trace the origin of the data with complete certainty. In turn, they can provide this lineage to their users, who can have confidence that the AI models they interact with are based on authentic information and are free from intentional manipulation. This framework will serve as a foundational step in safeguarding public trust in AI-driven systems. The Grass sovereign rollup will include a ZK processor, enabling metadata to be efficiently batched for validation while establishing a permanent lineage for each dataset Grass produces.
This innovation offers multiple advantages: it strengthens defenses against data poisoning, supports transparency in open-source AI, and paves the way for greater user insight into the AI models we engage with daily.

The storage of large datasets and lineage metadata on cryptographic rails creates a clear, unchangeable ledger that records data storage, access, and any alterations over time, ensuring transparency and immutability in the data's history. On top of the benefits of immutable, censorship-resistant data provenance guarantees, we also find that onboarding the long-tail of storage devices from around the world drives the price of storage down, making the decentralized storage solutions cheaper than the centralized alternatives. This is further enabled by Solana’s high data availability & Metaplex’s token innovations.
Real-time data access for AI models
AI models have improved primarily through scaling compute and parameters (more training and higher parameter training lead to better models). This has typically followed a power law relationship where you need exponentially more resources for linear improvements in performance, meaning that costs grow exponentially while improvements grow logarithmically.

Compute provision is typically handled by centralized (AWS, Azure and GCP) and decentralized (Akash, ionet, Render) compute marketplaces on the supply-side, as well as GPU companies (such as Nvidia with their H100s). As there isn’t enough supply, marketplaces typically charge a premium to AI labs.
On the data side, LLMs typically train on large datasets. The process for training LLMs is data inefficient, large amounts of data are fed into models, which requires extensive compute. Models as a result can be overfit, and are not applicable for real world use cases.

An alternative approach is to feed limited amounts of highly applicable and relevant data (high quality data) to LLMs, which requires less compute power and reduces the chances of overfitting models.
While utilizing high-quality, structured data during training is important, the age and relevance of data is equally crucial. Static historical datasets, no matter how well-curated, can become outdated quickly. This highlights the need for not just better structured data, but also more current data that reflects real-world conditions and changes.
Live context retrieval enables AI models to access and process real-time data from the internet during inference, rather than relying solely on training datasets.
AI models face several limitations:
Training on historical data with specific cutoff dates
Inability to access current information without additional infrastructure
Potential inaccuracies regarding recent events
Data value diminishes rapidly, with recent information providing greater utility than historical data. Real-time pricing delivers superior commercial and financial applications, while current pricing and sentiment monitoring are essential for market research. Recent data enhances AI response accuracy by providing current context and reduces hallucination when handling queries about recent events.
Grass was initially focused on providing datasets to hedge funds and retail firms, and later expanded to serve AI labs through these datasets. They now deliver both historical datasets and real-time web scraping (LCR) to AI labs and verified institutions.
Grass Protocol's infrastructure and architecture leverage millions of distributed nodes accessing websites through residential IP addresses. This network infrastructure enables real-time web scraping with parallel processing of millions of requests.
Google's DeepMind released a paper called SCoRE, which allows LLMs to self-improve without the need for external interference. LLMs can self-improve through reinforcement learning by generating their own data.
LCR, real-time data, enables models to utilize the most recent information and data online to self-improve through reinforcement learning. It also enables models to benefit from the same kind of data it will actually work with when it's deployed (put into real use).
Potential revenue streams and business models

H/t @grassbull
Data licensing deals are typically shrouded in secrecy and the specific details of each deal, such as dollar cost per photo / gigabyte / video / token, remain unknown. However, we can piece together the data from some of the known data licensing agreements that are publicly available.

A data licensing deal allows companies to access and utilize external datasets in exchange for payment, enabling them to enhance products or train AI models. For example, an AI firm may license data from Reddit, obtaining access to its extensive public user-generated content. Key deal components include:
Scope and Access: Specifies what data is accessible (e.g., comments, metadata), along with static or dynamic update requirements.
Usage and Compliance: Details permissible uses, often restricting resale or competitive usage, and enforces data anonymization for privacy compliance.
Payment and Duration: Typically structured as either a flat fee or usage-based pricing, with defined contract length and renewal options.
Data Security and IP Rights: Establishes data ownership, derivative rights, and security protocols to protect the data from breaches.
Data licensing deals like these facilitate the acquisition of high-quality datasets essential for training sophisticated AI systems while balancing IP rights and privacy obligations for both the data provider and the buyer and we have seen multiple high profile deals become public recently:
Shutterstock
Shutterstock, a leading marketplace for images, videos, and other media, has been licensing its extensive content library to train AI models, driving significant revenue growth since 2021. As of February, Shutterstock’s collection includes 771 million images, 54 million videos, 4 million audio tracks, and 1 million 3D models, establishing it as a key resource for AI-driven applications across industries.

Shutterstock has secured major agreements with "anchor customers" like Meta Platforms Inc., Alphabet Inc., Amazon.com Inc., Apple Inc., and OpenAI, with each contributing around $10 million in annual revenue, according to Reuters. The six-year partnership signed with OpenAI in 2023, along with the latest deal announced with Reka AI in June, further solidifies Shutterstock’s role in the AI training data market. The company is projected to earn $138 million in revenue from data, distribution, and service initiatives this year, with expectations to grow this figure to $250 million by 2027.
The San Francisco-based social network has signed licensing deals totaling $203 million, with contract terms ranging from two to three years, and is pursuing additional agreements to expand its portfolio. In January, the company secured a $60 million annual deal with Alphabet Inc.’s Google, providing ongoing and historical data access to support large language model training, a foundational technology for generative AI. According to its S-1 filing, the company anticipates recognizing $66.4 million in revenue from these contracts by the end of 2024.
Yelp
Perplexity is said to have licensed data from Yelp, though it is uncertain if this arrangement differs significantly from Yelp's pre-generative AI partnerships for sharing reviews, restaurant listings, and other information.
Yelp includes data licensing revenue within its "Other" category on its 2023 10k, which totaled approximately $47 million. However, this also encompasses other revenue streams. Notably, this category grew from around $21 million in 2020 to $47 million in 2023, hinting at a potential $25 million increase related to generative AI.
Wiley
Wiley, a well-established global publishing company specializing in academic, professional, and educational content, has been a trusted name since 1807. During their earnings call, Wiley reported a one-time payment of $23 million for previously published academic articles and books. The CEO indicated an interest in pursuing similar deals in the future. Wiley owns a portfolio that includes both academic journals and a substantial book publishing business.
Reuters
Reuters, a leading international news agency, reported an additional $22 million in revenue in its News Segment, largely driven by "transactional" content licensing for artificial intelligence. This resulted in a 6.5% increase in the News Segment's margin, suggesting that most of the incremental revenue came from content licensing.
The Market Price for Data

Many major market research firms have yet to assess the size of the opaque AI data market, where agreements are often undisclosed. Those that have, like Business Research Insights, estimate the global AI training dataset market at $3.91 billion in 2023, with a forecasted increase to $27.42 billion by 2032, reflecting a CAGR of 24.16%. Despite this growth potential, the industry remains nascent, with limited price discovery and no established market rates for data or standard costs per photo, GB, or video. Existing transactions are largely governed by custom contracts, complicating normalization and comparisons across deals. Again, we can look at some public deals to get a sense of what companies are willing to pay for this data:
Adobe
Adobe Inc. is sourcing short video clips featuring people in various actions, emotions, and basic anatomy shots (hands, feet, eyes) to fuel its AI-driven text-to-video generator, aiming to close the gap with competitors like OpenAI. Compensation averages $2.62 per minute of footage, with rates reaching up to $7.25 per minute.
Defined AI
Seattle-based Defined.ai, a data licensing firm serving prominent clients such as Google, Meta, Apple, Amazon, and Microsoft, offers a range of media content tailored for AI development, CEO Daniela Braga told Reuters. Pricing varies based on the buyer and content type. For image licenses, companies typically pay between $1 and $2 per image, while short-form video content is priced at $2 to $4 per clip. Long-form video licensing is substantially higher, ranging from $100 to $300 per hour. Text data, a high-demand category, is priced at approximately $0.001 per word. Defined.ai’s most sensitive content—such as images containing nudity—commands a premium, with rates between $5 and $7 per image.
Photobucket
Ted Leonard, CEO of Photobucket, based in Edwards, Colorado, revealed in an interview with Reuters that the company is in discussions with several tech firms to license its massive archive of 13 billion photos and videos. These assets are intended to support the training of generative AI models designed to create new visual content based on text prompts. Leonard noted that licensing fees are expected to range from $0.05 to $1 per photo, with video rates exceeding $1 each. Pricing structures vary widely, influenced by both the buyer’s needs and the specific types of visual content in demand.
Freepik
Freepik, a stock image platform and image bank, provides access to a vast library of photographs, illustrations, and vector images. With approximately 200 million images licensed at rates between $0.02 and $0.04 per image, the platform has secured contracts estimated at around $6 million per license with at least two AI firms. This scale of licensing underscores Freepik's growing role in supplying high-volume image data for AI development.
Potential Growth Areas
Having bootstrapped a network of over 2.5 million nodes, Grass is uniquely positioned to expand into a few key areas within the crypto AI stack. The areas we highlight here are hypothetical and the team has made no comments as to whether they will venture into these markets.
Incentivised Reinforcement Learning from Human Feedback
Reinforcement Learning from Human Feedback (RLHF) is a technique used to align AI behavior with human intentions by integrating human feedback throughout the training process. In this approach, human evaluators critically assess the AI's outputs, assigning ratings that facilitate the development of a reward model attuned to human preferences. This process necessitates high-quality human input, highlighting the importance of skilled labor in refining these models. Typically, this expertise tends to be concentrated within a few organizations capable of offering competitive compensation for such specialized tasks. Consequently, corporations with substantial resources are often in a better position to enhance their models, leveraging top talent in the field. This dynamic presents challenges for open-source projects, which may struggle to attract the necessary human labor for feedback without comparable funding or revenue streams. The result is a landscape where resource-rich entities are more likely to advance their AI capabilities, underscoring the need for innovative solutions to support diverse contributions in the development of AI technologies.
Crypto economic incentives have proven valuable in creating positive feedback loops and engaging top tier talent toward a common goal. An example of this tokenized RLHF has been Hivemapper, which aims to use crypto economic incentives to accurately map the entire world. The Hivemapper Network, launched in November 2022, rewards participants who dedicate their time to refining and curating mapping information and has since mapped 140 million Kilometers since launched in over 2503 distinct regions. Kyle Samani highlights that tokenized RLHF starts to make sense in the following scenarios:
When the model targets a specialized and niche area rather than a broad and general application. Individuals who rely on RLHF for their primary revenue, and thus depend on it for living expenses, will typically prefer cash payments. As the focus shifts to more specialized domains, the demand for skilled workers increases, who may have a vested interest in the project's long-term success.
When the individuals contributing to RLHF have a higher revenue from sources outside of RLHF activities. Accepting rewards in the form of non-liquid tokens is viable only for those with adequate financial stability from other sources to afford the risk associated with investing time in a specific RLHF model. To ensure the model's success, developers should consider offering tokens that vest over time, rather than immediately accessible ones, to encourage contributors to make decisions that benefit the project in the long run.
The Grass ecosystem could leverage crypto-economic incentives to coordinate and motivate its 2.5 million network nodes to provide human feedback on scraped datasets. By enabling global access and offering rewards based on merit, Grass has the potential to rapidly compete with centralized counterparts, creating a decentralized, scalable alternative for data annotation.
GPU & CPU Aggregation Marketplace
Before ChatGPT, GPU availability was already limited due to demands from crypto mining and other applications. However, since the rapid rise of AI models, GPU demand has skyrocketed, creating an unprecedented gap between supply and demand, despite sufficient global GPU capacity if fully organized. Many GPUs are underutilized across various sectors, such as:

Gaming PCs and Consoles: Powerful GPUs mostly idle outside gaming.
Corporate Workstations: Creative workstations could support AI tasks during off-hours.
Data Centers and Cloud Platforms: Often have spare GPU capacity.
Academic Institutions: High-performance GPUs are not always fully used.
Edge Devices and IoT: Collectively offer significant processing power.
Crypto Mining Rigs: Viable for AI workloads amid mining downturns.
This scattered "long-tail" of GPUs represents untapped potential for AI training / inference and distributed computing. Networks that use crypto incentives to coordinate the development and operation of essential infrastructure can achieve improved efficiency, resilience, and performance—though not fully realized yet—compared to centralized systems. While still emerging, the benefits of incorporating the long-tail of GPU power into Decentralized Physical Infrastructure Networks (DePIN) are already becoming apparent with cheaper:

The Ultimate Vision
Grass's scraping infrastructure currently operates with 2.5 million nodes, enabling complete Reddit data collection within a week and processing 15 million articles daily at 0.1% network capacity. Their 100 million node target would enable internet-scale web crawls, matching capabilities currently limited to Google and Microsoft.
Grass aims to become the primary data layer for AI by creating a decentralized knowledge graph of the internet that models can integrate for real-time data access. Their focus centers on real-time context retrieval for artificial intelligence models and multimodal training data provision.
Through residential IPs, Grass delivers unbiased internet views while preventing data poisoning via proof of request mechanisms. Their infrastructure maintains dataset-source lineage, ensuring transparency. Grass differentiates itself through exclusive focus on data infrastructure, avoiding direct competition with Google, Microsoft, and other artificial intelligence companies.
Grass's architecture leverages parallel processing via distributed nodes to surpass traditional scraping constraints while ensuring real-time data validation. This enables verified, unbiased data delivery across their network.
Market dynamics support Grass's growth potential, driven by demand for real-time, verified data and expansion into video, audio, and image formats. The industry prioritizes data quality over model scaling, emphasizing real-time access and verification - core strengths of Grass's infrastructure.2
Tokenomics
Token Utility
The GRASS token will serve as the backbone of the Grass ecosystem, enabling ownership of the network. Holders will derive utility via the following mechanisms:
Transactions & Buybacks: After decentralization, GRASS tokens will be used to facilitate web scraping transactions, dataset acquisitions, and LCR usage across the network.
Staking and Rewards: Users can stake GRASS to Routers, enabling web traffic flow through the network and earning rewards in return for enhancing network security. You can stake your GRASS here with ASXN LAB’s router:
Network Governance: Users can engage in shaping the Grass network by proposing and voting on improvements, determining partner organizations, and setting incentive structures for stakeholders.
Network Fees
All stakeholders within the Grass ecosystem are ultimately rewarded in GRASS tokens. The Grass Foundation offers purchasers the flexibility to pay in USD, USDC, or other supported tokens when consuming bandwidth, purchasing datasets, or utilizing the LCR. These network revenues are then converted to GRASS, which is then used to rewarding providers such as nodes, routers, and data providers for their support of and participation in the network, including through network resource access.
Network Staking & Security
GRASS is staked to routers to crypto-economically enforce compliance with network protocols. Routers are responsible for accurately facilitating bandwidth traffic and reporting resource usage per transaction. Currently, slashing is triggered manually, but as the network develops and achieves full decentralization, slashing is expected to occur autonomously.
When staking to routers, you will want to consider a few variables:
Performance - Selecting a high-performance router with strong uptime will maximize your yield, as these routers handle more traffic and earn greater rewards. Conversely, staking with a router that frequently experiences downtime can result in slashing (token burn), leading to potential losses on your stake.
Commission - Routers charge a commission on all the rewards / yield earned from their operation. On the Grass network, this commission generally falls between 5%-20%. Selecting a router with a lower commission will enable you to keep a large proportion of your yield from staking.
Grass Staking Analytics
During the bootstrapping of the network, the Grass foundation have allocated 3% (30M GRASS) of the token supply toward routers over 2.5 years:

This results in the following staking yield curve for GRASS:
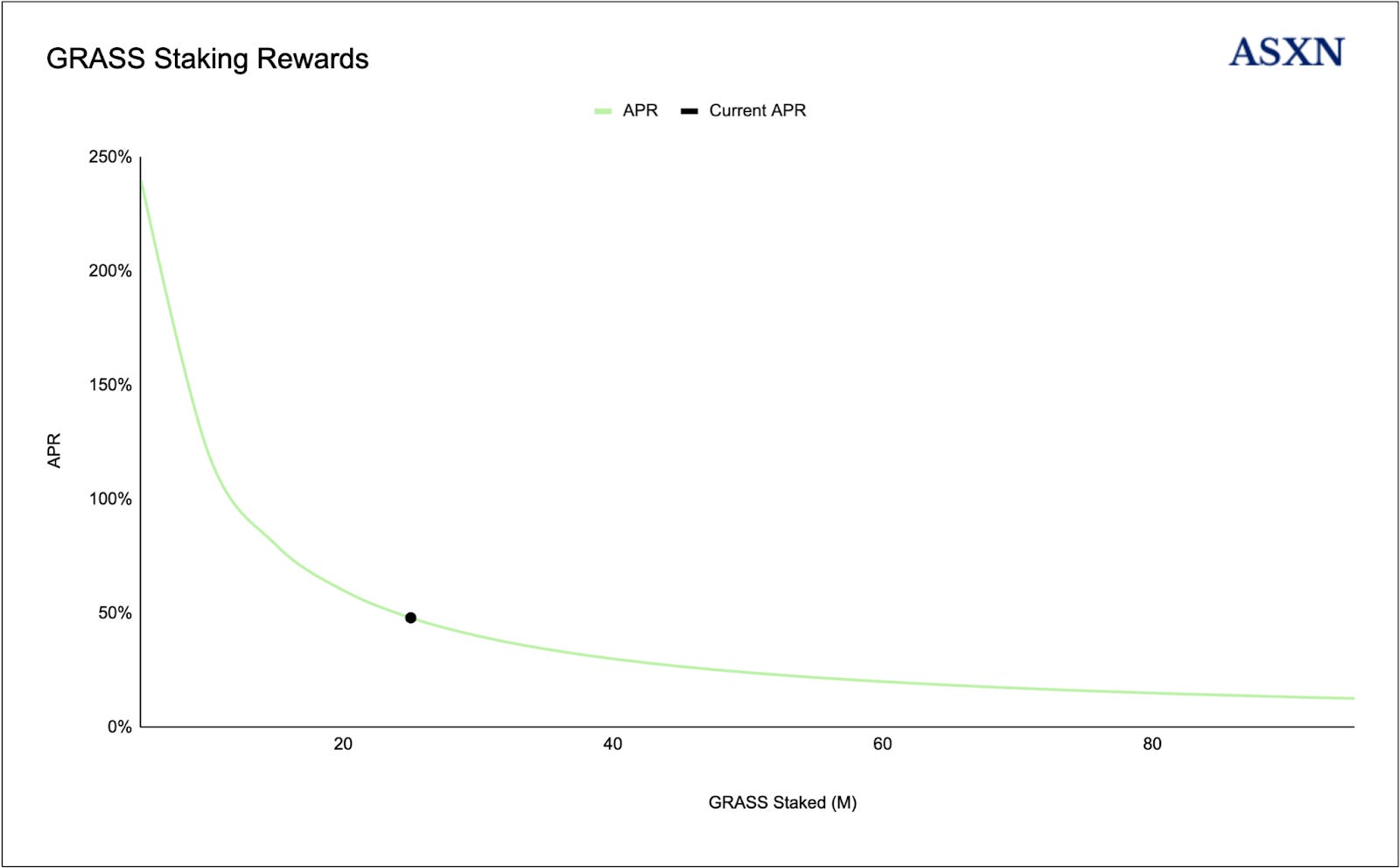
Currently, staking of GRASS yields 50% APY and has a 7-day unstaking period.

Supply
The total GRASS token supply is 1 billion tokens & the distribution is as follows:

At TGE on the 28th of October, 25% of the token supply will be unlocked, with 10% of that coming from the airdrop.

Airdrop One distributes 100,000,000 GRASS tokens (10% of the total supply) to early users and community members as follows:

9% allocated to users who accumulated Grass Points during Stage 1 (the Network Snapshot).
0.5% to holders of GigaBuds NFTs.
0.5% to users who installed the Desktop Node or the Saga Application.
The Grass tokens were distributed to point holders in 10 distinct epochs:
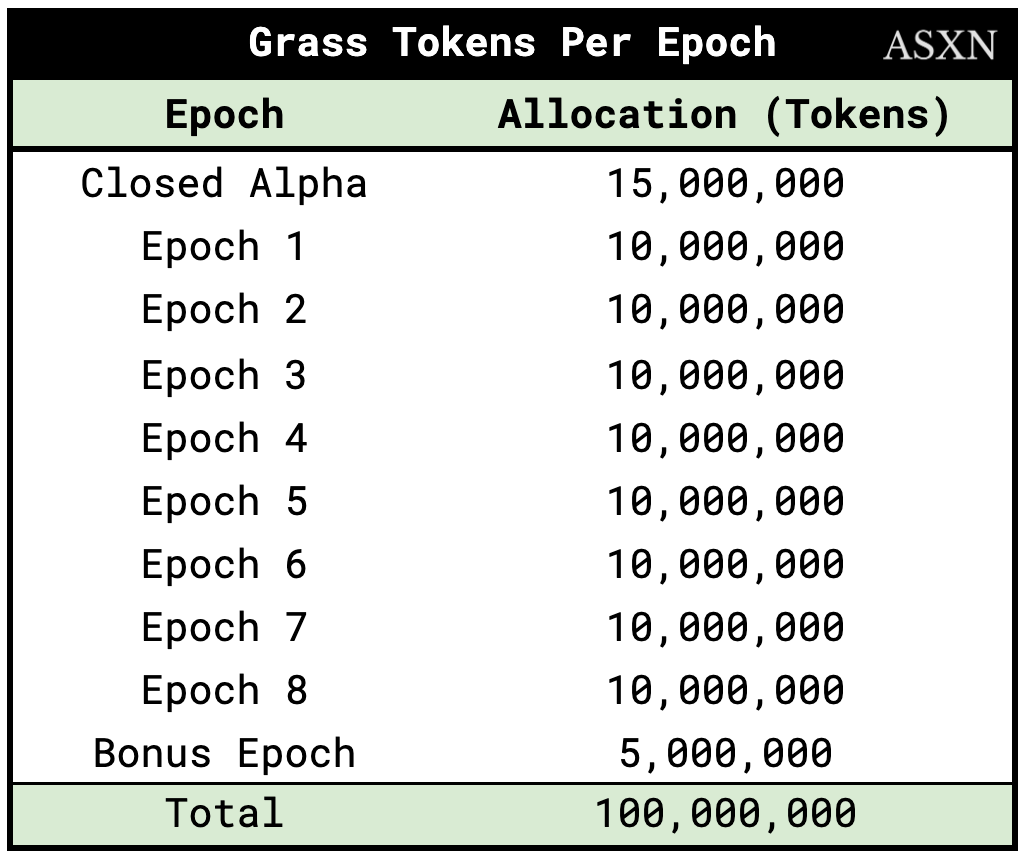
The 9% allocated to Grass points were distributed as follows:

We can see being early (Closed alpha, Epoch 1 & 2) made a huge difference when it came to the number of GRASS tokens you earned per tier.

We can visualize what being early to Grass looks like by charting the GRASS tokens earned per epoch as a tier 1 node.Of the total ~15.4k GRASS distributed to a user who remained a tier 1 node since the closed alpha, ~49% of tokens came from participating in the closed alpha.
Airdrop Claims

To date, 85.55% of the GRASS token airdrop has been claimed, with the team confirming that only 78 million GRASS tokens will ultimately be distributed. This has resulted in 68.79 million GRASS tokens claimed by over 2.5 million unique addresses, marking the GRASS airdrop as the most widely distributed airdrop to date. The Solana blockchain experienced significant congestion following the claim period’s opening, with the majority of tokens being claimed within the first 12 hours.
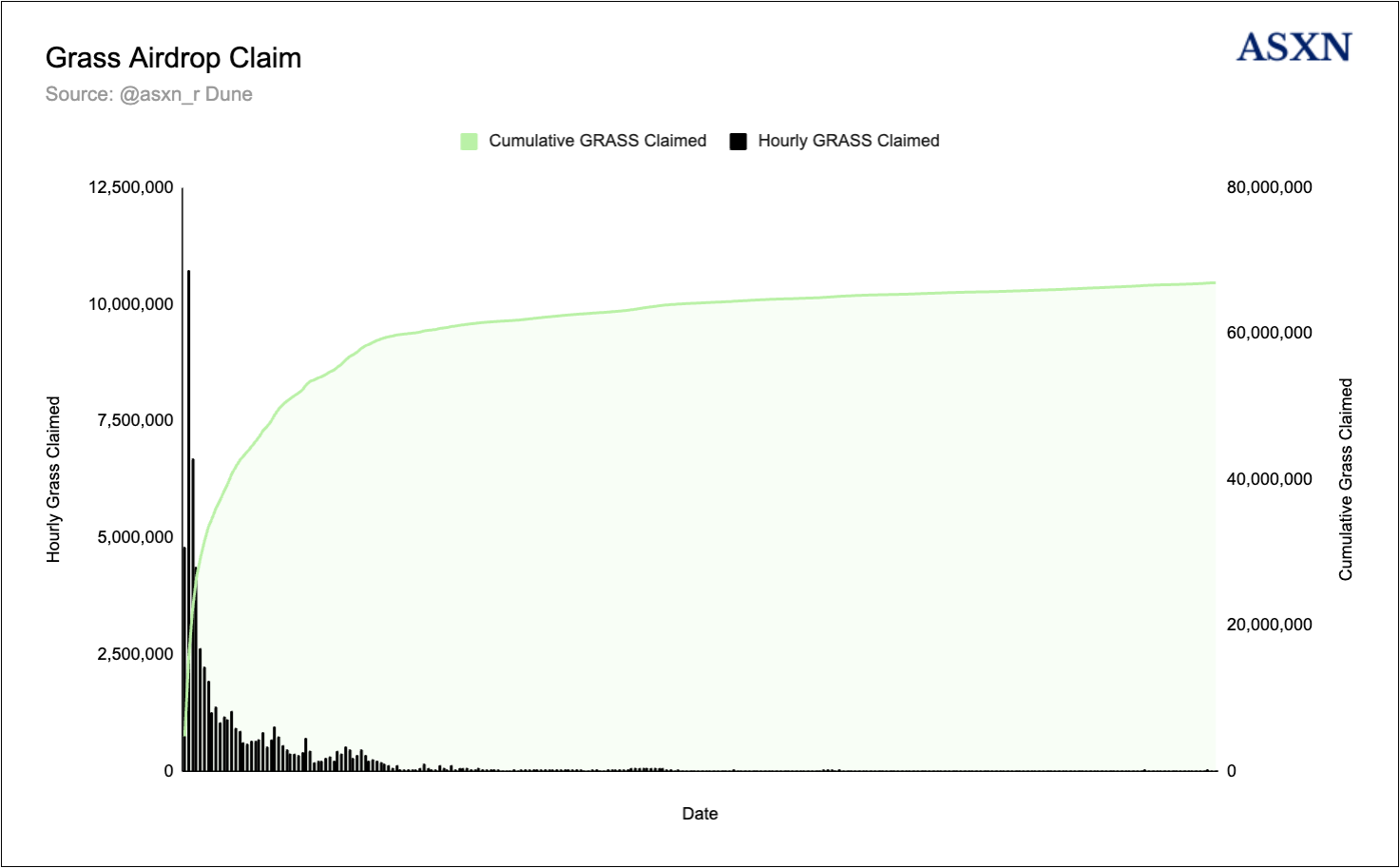
You can find our full dune dashboard here.
https://dune.com/asxn_r/grass-claims
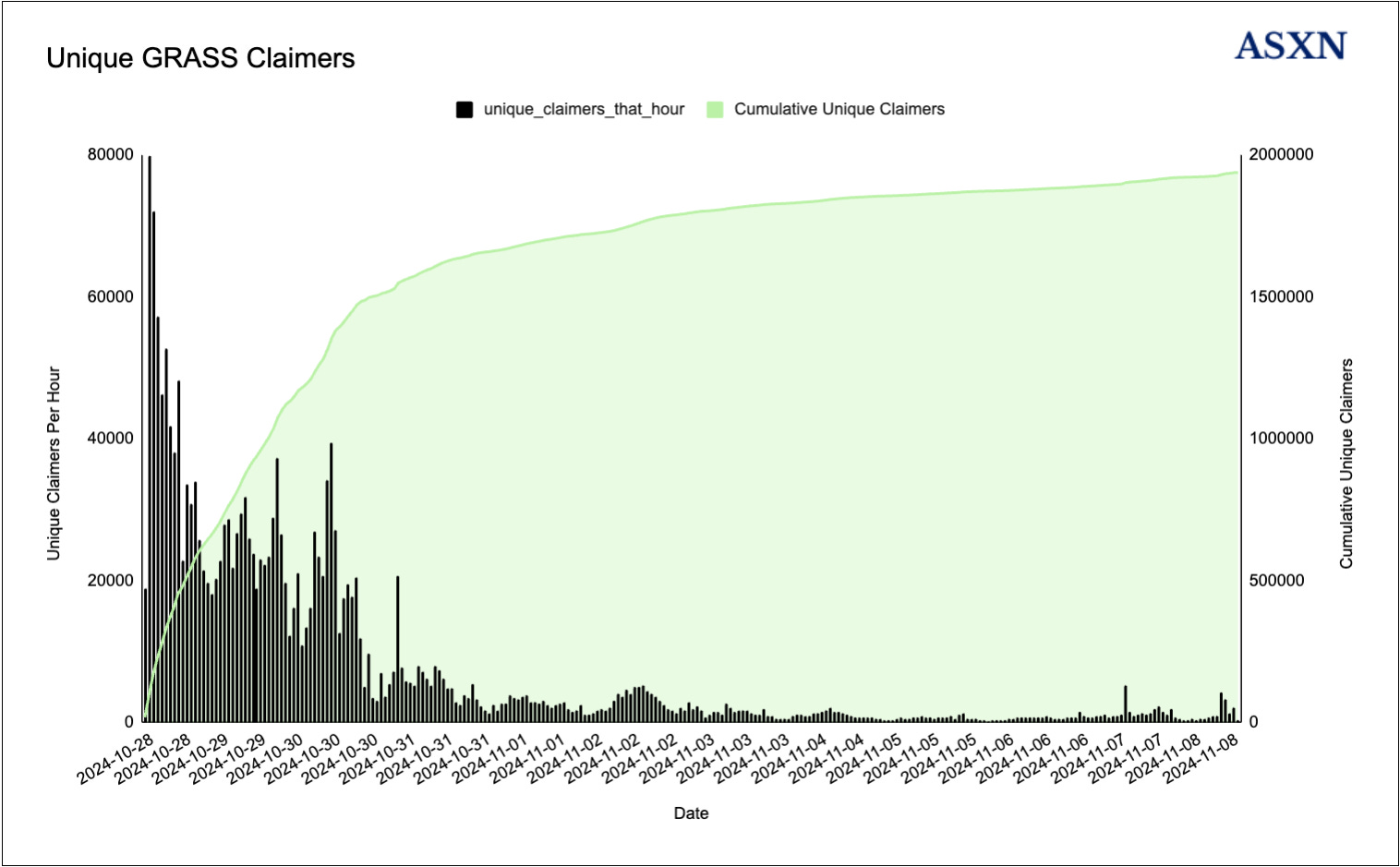
Token Emissions
The GRASS token will undergo an emission schedule as follows:

Core Contributors - A 1-year cliff and 3-year vesting, which includes current and future contributors. Locked tokens cannot be staked until they are vested. At the 1 year cliff, 25% of the core contributor allocation will be unlocked, and the remaining 75% will vest over the 3 years.
Early Investors - A 1-year cliff and a 1-year vesting period. Locked tokens cannot be staked until they are vested. At the 1 year cliff, 50% of the early investor allocation will be unlocked, and the remaining 50% will vest over the 1 year.
Community - Making some assumptions based upon the emission schedule found in the Grass documentation, we believe the community allocation has the following emission schedule:
Foundation & Ecosystem Growth - 150M GRASS tokens unlocked at TGE, with 78M GRASS tokens vesting linearly over a 3 year period from TGE. Held by the foundation and reserved for use as directed by DAO governance. This allocation will support community & growth initiatives like network upgrades, partnerships, research, and development aimed at scaling the ecosystem.
Airdrop One - 100M GRASS tokens unlocked at TGE. No vesting.
Router Incentives - 0 GRASS tokens unlocked at TGE. 30M GRASS tokens vesting linearly over a 2.5 year period. An initial pool of rewards has been set aside to incentivize routers and support early infrastructure development. This pool will help ensure that routers, which facilitate bandwidth traffic and reduce latency, are properly incentivized until the network matures and can sustain itself through network fees.
Future Incentives - A 3 year linear vest for the full 170M GRASS token allocation. Future Incentives will focus on retroactive programs that recognize early contributors and reward creators who build valuable content or tools for the network. Interestingly, Grass has denoted the initial airdrop as ‘Airdrop One’, potentially signaling there could be more airdrops in store but this is speculation on our part.
Risks and Challenges
Regulatory considerations
The Grass business model and protocol mechanics operate in a legal gray area across many jurisdictions, especially with the recent surge in generative AI data scraping. This widespread practice has triggered a wave of copyright lawsuits and regulatory scrutiny, with publishers increasingly blocking scraping through code. A key consideration for the Grass protocol is navigating the regulatory and legal uncertainties surrounding AI data use, as the situation is constantly evolving and regulation remains in its infancy. With numerous ongoing cases, the framework for AI data usage is beginning to take shape, though the ultimate outcomes are far from settled.
New York Times Co v Microsoft Corp et al, U.S. District Court, Southern District of New York, No. 23-11195.
The New York Times filed a lawsuit against OpenAI and Microsoft in December 2023, alleging that they used millions of the newspaper's articles without authorization to train their chatbots. This case joins other legal actions by writers and content creators seeking to restrict AI companies from scraping their work without compensation. Novelists like David Baldacci, Jonathan Franzen, John Grisham, and Scott Turow also filed suit against OpenAI and Microsoft in Manhattan federal court, claiming that AI systems may have appropriated tens of thousands of their books. OpenAI and Microsoft argue that their use of copyrighted materials for AI training qualifies as "fair use," a legal principle that allows certain unlicensed uses of copyrighted content. According to the U.S. Copyright Office, "transformative" use—defined as adding new purpose or character to the original work—is more likely to be considered fair. The Times’ lawsuit highlights instances where the defendants' chatbots allegedly provided users with near-verbatim excerpts from its articles.
Raw Story Media v. OpenAI Inc, U.S. District Court for the Southern District of New York, No. 1:24-cv-01514.
On November 7th 2024, a federal judge in New York dismissed a lawsuit against OpenAI, in which news outlets Raw Story and AlterNet claimed that the AI company had improperly used thousands of their articles to train its language model, ChatGPT. Filed in February, the lawsuit alleged that OpenAI utilized the articles without permission and that ChatGPT could reproduce their copyrighted content upon request. Unlike other recent lawsuits, this complaint focused on accusations that OpenAI had unlawfully removed copyright management information (CMI) from the articles, rather than directly arguing copyright infringement.
U.S. District Judge Colleen McMahon ruled that the news outlets had not demonstrated sufficient harm to sustain their lawsuit but permitted them to submit a revised complaint. However, she expressed doubt that they would be able to "allege a cognizable injury."
Artificial Intelligence Act: deal on comprehensive rules for trustworthy AI
In December 2023, the EU reached a provisional agreement on new AI regulations, positioning it to become the first major power to enact AI laws. The rules require systems like ChatGPT to meet transparency standards, including technical documentation, compliance with EU copyright, and summaries of training data. Consumers would have the right to file complaints and receive explanations for AI decisions, with fines for violations ranging from 7.5 million euros ($8.1 million) or 1.5% of turnover to 35 million euros or 7% of global turnover.
Meta Platforms, Inc. v. Bright Data Ltd., 23-cv-00077-EMC
On January 23rd, 2024 a U.S. Federal Court’s ruling in Meta v. Bright Data reaffirmed the public’s right to access and collect public web data. Judge Chen of the Northern District of California ruled in favor of Bright Data in its data scraping case against Meta, determining that Meta’s Terms of Service do not prohibit “logged-off” scraping of publicly available data from Facebook and Instagram. Meta had argued that scraping violated its terms, but the court found that Bright Data was not a "user" and thus not bound by Meta’s Terms while logged out. Additionally, the court held that once Bright Data terminated its accounts, Meta could not enforce a “survival” clause that aimed to prohibit scraping in perpetuity, as this could create information monopolies contrary to public interest. This ruling could have a broad impact on the data scraping industry.
Overview
These recent cases underscore a shifting legal and ethical landscape around data scraping and AI training. U.S. courts, as seen in Meta v. Bright Data, have upheld the legality of scraping publicly accessible data without user login requirements, reinforcing open data access rights. However, cases like NYT v. Microsoft/OpenAI reveal mounting challenges against using scraped copyrighted material for AI training, with content creators increasingly pushing back against unlicensed use and seeking compensation. The EU’s AI Act sets a pioneering regulatory framework, mandating transparency and compliance with copyright for AI training data and establishing strong consumer rights and penalties. While data scraping of public content appears legally defensible, selling this data for commercial gain without creator compensation is ethically contentious and likely to face stricter regulation. Together, these rulings and regulations signal a future where AI companies may need to adopt more transparent, equitable approaches to data usage and copyright compliance.
Competition
As is usual for DePIN and AI protocols, Grass faces competition from centralized counterparts, the major ones being Perplexity and OpenAI, who offer models with real-time data access.
Perplexity and OpenAI employ several methods to access and deliver current information to users. They utilize web crawling and indexing techniques to gather online information from various internet sources, enabling comprehensive data collection. Both platforms also have live data connection capabilities, allowing them to retrieve the most recent results and provide accurate, factual responses, and are able to conduct real-time searches to pull current data from the internet, ensuring the delivery of up-to-date information.
Data quality and poisoning risks
Data poisoning refers to the deliberate manipulation of training datasets. This manipulation can occur through:
Server-side poisoning, where websites serve altered information to detect non-human visitors
Retroactive poisoning, where actors modify collected datasets by introducing biased or incorrect information.
Data poisoning affects training data quality for large language models, real-time data collection, market competition between data-gathering companies, price aggregation systems, public opinion, and AI system trustworthiness. Model reasoning capabilities and output reliability are particularly vulnerable.
Websites typically employ sophisticated detection methods using IP addresses and device fingerprints, serving different content upon detecting non-residential or data center IPs. They recognize automated scraping attempts and modify data accordingly. Through retroactive manipulation, actors modify existing datasets post-collection, inserting subtle biases or incorrect information, often driven by political or commercial interests.
The potential consequences are not limited to unreliable training data and biased AI models that affect millions of users. Data poisoning can influence public opinion through biased AI responses, affect market competition and pricing, and potentially alter nation-state and political trajectories through subtle influence.
Currently, Grass combats data poisoning through both technical and structural solutions. Technical approaches include residential IP usage and proof of request mechanisms. For structural solutions: Grass' architecture and design includes proof systems for web requests, ZK TLS verification, and Merkle trees for data validation.
Disclaimer:
The information and services above are not intended to and shall not be used as investment advice.
You should consult with financial advisors before acting on any of the information and services. ASXN and ASXN staff are not investment advisors, do not represent or advise clients in any matter and are not bound by the professional responsibilities and duties of a financial advisor.
Nothing in the information and service, nor any receipt or use of such information or services, shall be construed or relied on as advertising or soliciting to provide any financial services.
